
(New Approach🔥) LLMs + Knowledge Graph : Handling Large documents and data for any industry — Advanced
Most of the Real World data replicate Knowledge graph. In this messy world, one will hardly find a linear data of information.

Most of the Real World data replicate Knowledge graph. In this messy world, one will hardly find a linear data of information. AI system needs to understand non-linear data structure like graphs which depicts any human brain.
There are multiple cases where these knowledge graphs could be groundbreaking:
Any Business function — Most businesses has heirachical form of system and process in their functioning. One could leverage this to create a Knowledge Graph for each sub-groups
Data modelling — Data is normalized and stored in multiple dimension and fact tables in a warehouse which is nothing but a knowledge graph.
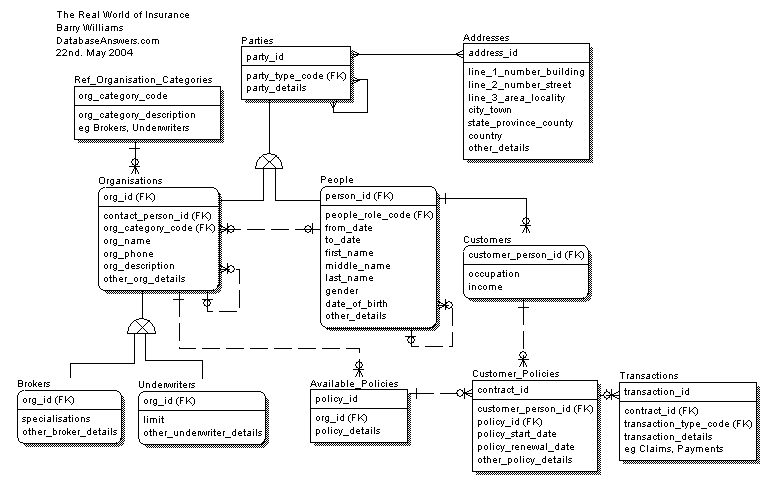
All Social networking sites like Facebook, Instagram etc. follows Graph data structure to show connections and nearby contacts.

Why KGs are effective?
Captures Non-Linearity
Lots of Context with relationships and dependencies
Segmentation of data for granular and detailed level information.
But to use these LLMs, one need to create a Knowledge Graph from your own data and combine with LLMs to extract output.
Knowledge Graph Creation:
Creating a Knowledge graph from your data varies with domain. And many of these data are Texts, Folder with multiple files, Code Repository etc.
I will show how to create a knowledge graph from code repository which includes codebase modelling.
Codebase modelling is where you extract all the relationships between different files using functions imported from other files.
I have used ast library to extract imports from a file mentioned in code below. Currently it is limited to only python files but can be extended to other languages too.
with open(file_path, 'r', encoding='utf-8') as file:
tree = ast.parse(file.read(), filename=file_path)
imports = {}
for node in ast.walk(tree):
if isinstance(node, ast.Import):
for alias in node.names:
alias.name= add_prefix + alias.name + '.py'
if alias.name in filtered_files:
imports[alias.name] = None
elif isinstance(node, ast.ImportFrom):
if node.module is not None:
node.module= add_prefix + node.module + '.py'
imports[node.module] = [name.name for name in node.names]
return importsThere are multiple GraphDatabases and libraries to create a graph like Neo4js, Nebulagraph, networkx.
I have used networkx to build and plot the graph using the code below.
for root, dirs, files in os.walk(folder_path):
for file in files:
head = file
for tail,functions in imports.items():
if functions is not None:
for relation in functions:
dfs.append(pd.DataFrame({'head': [head], 'relation': [relation], 'tail': [tail]}))
df = pd.concat(dfs, ignore_index=True)
for _, row in df.iterrows():
graph.add_edge(row['head'], row['tail'], label=row['relation'])
return graph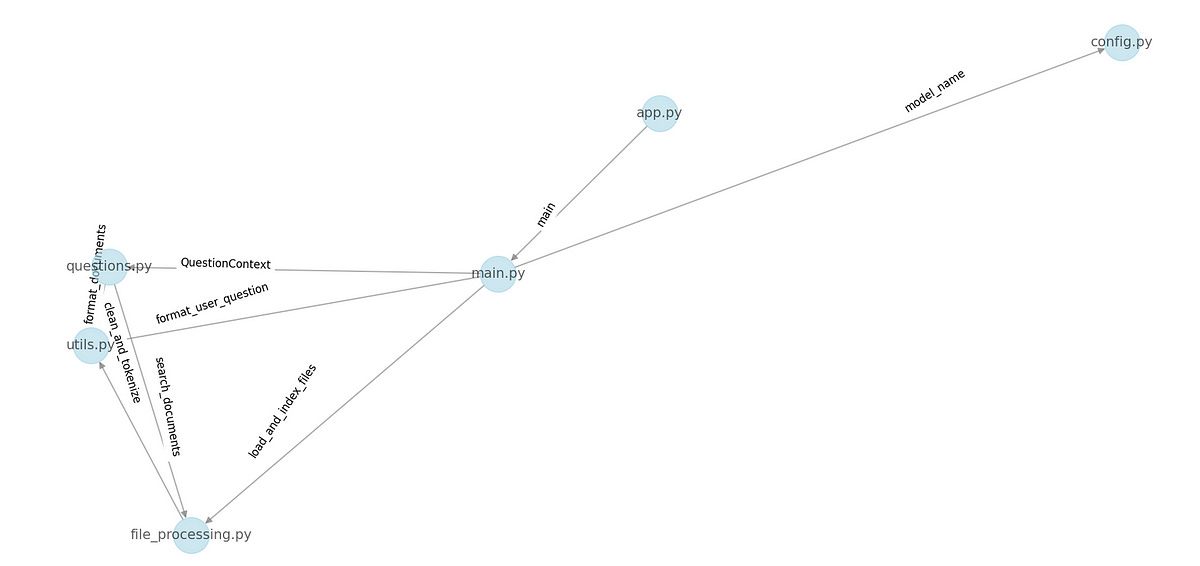
The above is the Knowledge Graph of the codebase where nodes are files and edge shows the functions which are imports done by other file showing inter-dependency and relationships between files.
Combining Knowledge Graphs with LLM:
Once Knowledge graph is created, its time to combine with LLMs to get result.
There are few ways to do so:
Langchain Graph Index and Graph Retrieval method
You can use Langchain in-built Graph Index and Retrieval classes but they are not so good in capturing context either with texts as input or Repository. Retrieval is also bad which requires exact phrases in prompt to find the the relevant sub-graph and there is no room for tolerance in spelling or grammatical mistakes.
2. Flexible Knowledge Graph RAG (My own)
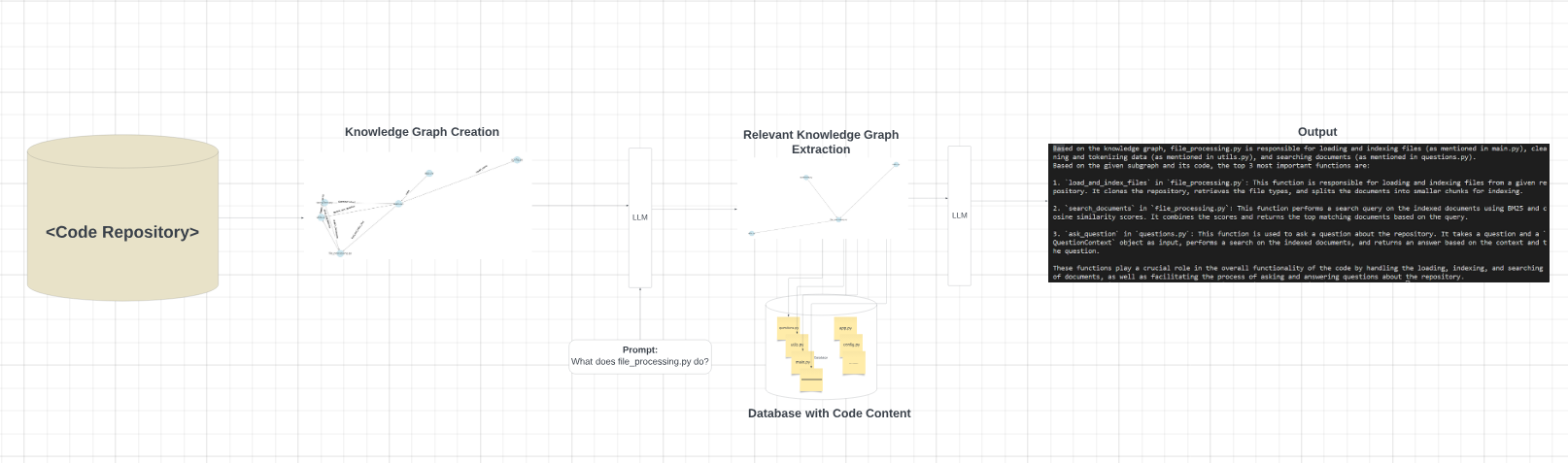
The above Knowledge Graph RAG pipeline is created by me which is giving tremendous results capturing all context and scope of the query.
Knowledge Graph Retrieval
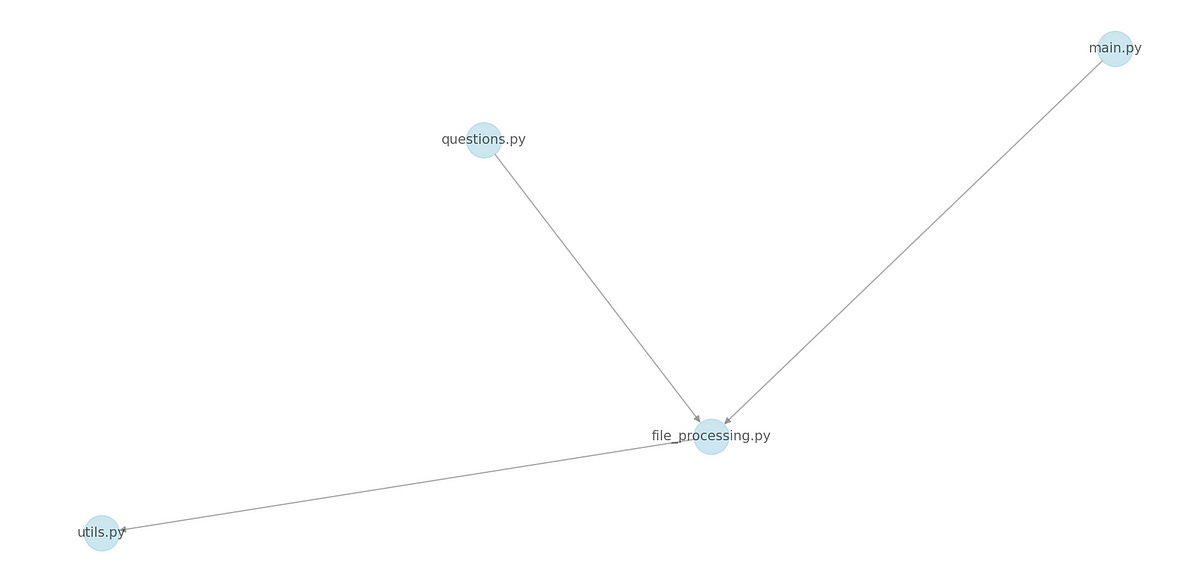
Knowledge graph created from code repository is fed into LLM along with prompt to produce relevant sub-graph according to the prompt asked. This is a magical step since we are only capturing the file (“file_processing.py”) and its relations with other files helping us to intelligently provide only sufficient information according to prompt.
What’s New?
Most of the implemented methods search the whole graph by extracting the relevant words from prompt and comparing against the nodes to find relevant sub-graph. But it has lot of issues as it doesn’t cover up the tolerances in writing any prompts which can include spelling mistakes etc and give bad result. This is the reason why we need a LLM layer to avoid these issues.
Secondly, It extract the full scope of the file which helps us to find knowledge depth and the level we want our answers at. It can easily scope in and scope out to navigate across different sub-graphs
Here comes the Mindblowing revelation. We haven’t even given the content of code but only its dependencies and relations with one another which will take very few token size even for huge code repositories while still giving major context to LLMs.
Final Blow
Now, With the relevant Sub-graph, we will access the code content only from relevant files present in the connections [utils.py, main.py, questions.py] and fed into LLM to produce output
Below is the output for prompt :”What does file_processing.py do?”
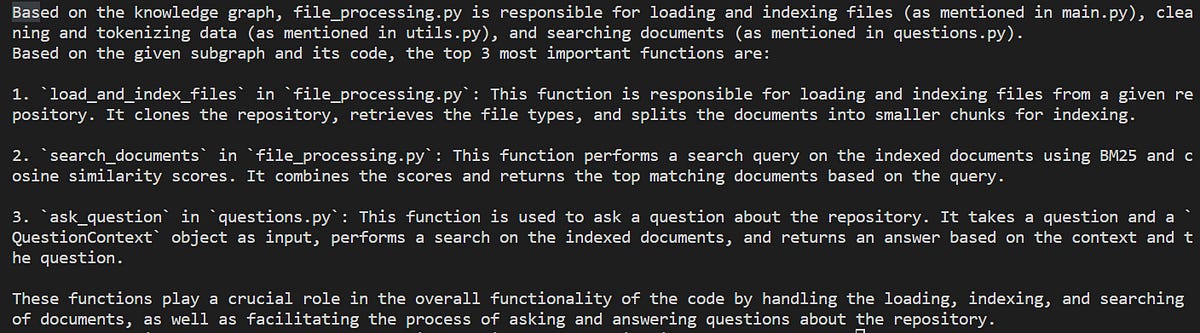
The output is outstanding in many ways:
It not only gives you what file_processing.py does but also provides the information of its connections and relations with other files.
It gives all the important functions in the scope of file_processing.py
and the list goes on.
The above Knowledge graph RAG pipeline has two major USPs:
Handling Large Scale Documents and Data
Problem:
LLMs have a major restriction of token size. More the token size, higher will be the cost. Thus we resort to chunking and other similar methods which has a major drawback of information loss due to no context of how each chunk is related with another.
So, only top chunk is chosen according to similarity search which might not contain the information you are looking for as it just matches the phrases present in prompts with chunks.
Idea:
But if we somehow create a Knowledge graph which captures the relationships between chunks avoiding any information loss, we can easily deal with any large scale documents and data.
Capturing Scope of Query [System 2 thinking like agents]
It captures the scope and level of the query making LLMs understand where to dig in and find answers. It is depicting the system 2 thinking which is how we humans think.
Future Extensions:
Combining it with Normal RAG methods for improving the performance
Use Map_Reduce approaches to summarize the documents combining with Knowledge graph
Build Agents on the top of it to make it more autonomous.
Generalize it to any Industry Scale documents or data.
Thank you for reading the blog.
If you want the full code of above approach, connect me on linkedin(https://www.linkedin.com/in/vaibhaw-khemka-a92156176/). Happy to collaborate.
I will be working on these ideas in future.
Stay Tuned!!